
линейная регрессия, классический метод наименьших квадратов
- Линейная регрессия - несколько слов введения
- Классический метод наименьших квадратов
- Интерпретация коэффициента направления и свободы выражения
- Линейная регрессия - простой пример
- Какие остальные?
- Условия для метода наименьших квадратов
- Примеры нетипичных наблюдений:
- Оценка оценки регрессионной функции
- коэффициент детерминации
- коэффициент совместимости (сходимости)
- коэффициент остаточной изменчивости
- критерий значимости для коэффициента линейной регрессии
- Линейная регрессия в электронной таблице
- диаграмма
- LINEST (ЛИНЕЙН) функция
- Статистический пакет в электронной таблице
- Линейная регрессия в R
- линейная регрессия в R-коде
- линейная регрессия в R - графе
- линейная регрессия в R - расчетные параметры
- линейная регрессия в R - остаточные графы
- линейная регрессия - удаление данных из модели
- Интерполяция и экстраполяция
- Дополнительная информация о линейной регрессии
Линейная регрессия - это тема, с которой я сталкиваюсь очень давно, и я все еще откладываю ее позже. Потому что не особо сложно рассказать о круговая диаграмма , Это легко объяснить среднее арифметическое или стандартное отклонение , И линейная регрессия такой большой слон. Но больших слонов тоже можно есть, только начинать нужно по частям. И я думаю, что именно так мы можем шаг за шагом справляться с нашим регрессивным слоном, и после прочтения статьи все будут знать, что происходит.
Линейная регрессия - несколько слов введения
Последняя запись касается точечный график , Я показал, как нарисовать связь между двумя переменными. Ранее я показал, как рассчитать, происходит ли это линейная корреляция , В линейной регрессии это еще не все. Корреляция говорит нам, какова сила зависимости между переменными. Регрессия говорит нам о форме этой зависимости. Таким образом, с этими точками на графике мы попытаемся сопоставить прямую линию, которая будет лучше всего характеризовать отношения между x и y. И как только у нас будет такая функция, мы можем проанализировать отношения между переменными и даже предсказать y на основе недавно изученного x.
Линия, которую мы ищем, будет описываться формулой y = ax + b . Это самая простая запись. В профессиональной литературе вы можете найти намного более сложные штампы, а также описания, которые я трижды читал сам и не понимаю, что происходит. Но мы здесь не для того, чтобы понять всю математическую статистику, которая стоит за этим. Начнем с того, что легко понять.
Строка y = ax + b содержит четыре разных буквы.
y - объясненная переменная (иногда также называется зависимой)
x - объясняющая переменная (иногда также называется независимой)
а - коэффициент направления, коэффициент регрессии у относительно х ( уклон )
б - перехват
Большинство читателей, вероятно, помнят, что в школе нужно было найти прямую линию, проходящую через две точки. Если у нас было две таких точки, этого было достаточно, чтобы решить систему уравнений, и у нас уже была формула.
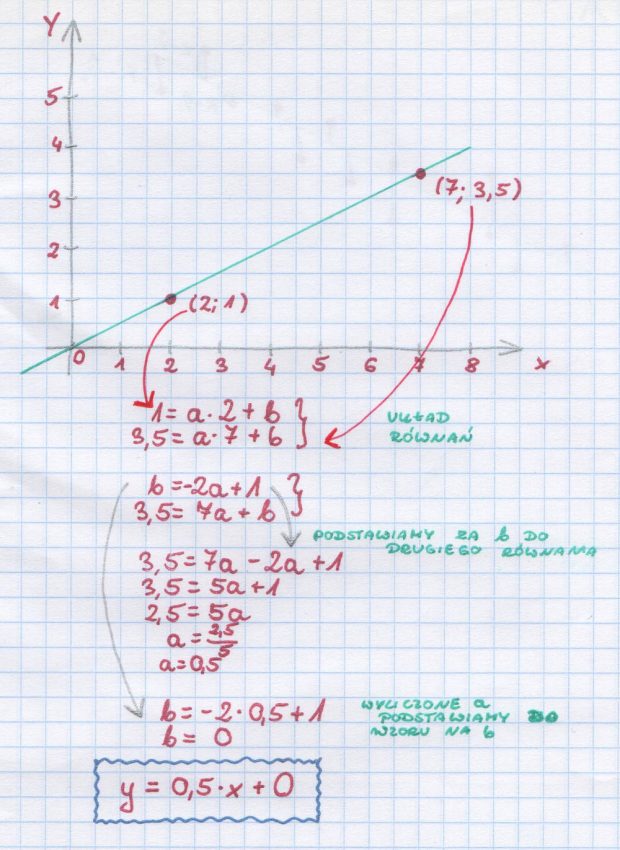
Классический метод наименьших квадратов
В случае многих точек это не так прямо. И на самом деле никогда не бывает ситуации, когда простой человек сможет пройти через каждый из пунктов. Таким образом, вы должны выбрать метод, который позволит вам найти наиболее оптимальную прямую линию, которая наилучшим образом описывает отношения между x и y. И, конечно, существует множество таких методов. Вы можете услышать о методе наибольшего доверия, двухточечном методе, срединной регрессии и т. Д. И среди этих методов метод наименьших квадратов является наиболее популярным.
Поскольку мы планируем сосредоточиться на том, что является наиболее популярным, я немедленно напишу вам, как метод наименьших квадратов используется для оценки значений a и b. Предполагается, что мы будем искать минимум для суммы квадратов разностей наблюдаемых значений и теоретического значения (рассчитанного по нашему уравнению).
Вот некоторые образцы сейчас. Мы ищем минимум для суммы квадратов:
\ (Min \ sum_ {я = 1} ^ {N} (X_ {я} - \ Шляпа {у} _ {я}) ^ {2} \)
Мы можем написать то же самое таким образом:
\ (Мин \ sum_ {= 1} ^ {N} (X_ {I} -ax_ Б {г}) ^ {2} \)
Помимо любых преобразований, давайте просто запомним, что для вычисления коэффициента направленности мы используем формулу:
\ (А = \ гидроразрыва {\ sum_ {= 1} ^ {N} (X_ {я} - \ Overline {х}) (у- {я} - \ Overline {у})} {\ sum_ {= 1 } ^ {п} (X_ {I} - \ Overline {х}) ^ {2}} \)
Вычислить значение свободного слова уже просто. Достаточно заменить среднее арифметическое x и среднее арифметическое y на формулу.
\ (В = \ Overline {у} -a \ Overline {х} \)
Таким простым способом мы вычислили a и b из нашего уравнения и можем дать формулу линейной регрессии.
Стоит отметить, что с помощью метода наименьших квадратов мы имеем дело с оценщик линейный, последовательный, без нагрузки и наиболее эффективный.
Интерпретация коэффициента направления и свободы выражения
Как только мы вычислим параметры линейной регрессии, стоило бы знать, что они означают.
Что касается значения коэффициента направленности, то оно говорит нам о влиянии изменения единицы x на переменную y. Если a положительно, увеличение единицы xo означает, что мы можем ожидать среднего увеличения единиц yoa. Если a имеет отрицательное значение, то при увеличении xo на единицу, y в среднем уменьшается на единицу.
Слово free говорит нам, какое значение y следует ожидать для нуля x. Очень часто оно не имеет смысла - потому что оно может находиться за пределами диапазона данных, для которого мы анализируем регрессию. Например, если мы интерпретируем взаимосвязь между ростом и весом, мы начинаем рассмотрение с ненулевого значения x. Тот, кто ростом 0 см, не может ничего взвесить, не существует и не может быть осмысленно интерпретирован в этом случае.
Линейная регрессия - простой пример
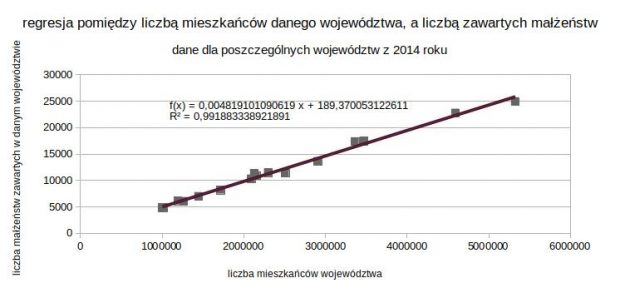
Когда я писал текст о примерах коэффициента корреляции, среди прочего я показал пример корреляции между количеством жителей данной провинции и количеством браков, заключенных в 2014 году. Линейная корреляция имела очень высокий коэффициент (0,9959), поэтому я думаю, что это будет хорошим примером для демонстрации линейной регрессии. Мы используем выходные данные:
провинцияx (население)y (брак)
Нижнесилезское 2908457,00 13599,00 Куявско-Поморское 2090836,00 10294,00 Люблинское 2151836,00 10911,00 Любушское 1020767,00 4875,00 Лодзинское 2508464,00 11405,00 Малопольское 3364176,00 17361,00 Мазовецкое 5324519,00 24924,00 Опольское 1002575,00 4822,00 Подкарпатское 2128483,00 11287,00 Подляское воеводство 1193348,00 6135,00 Поморское воеводство 2298811,00 11461,00 Śl 45skie 4593358,00 22765,00 Świętokrzyskie 126565454545 , 00 Варминско-мазурские 1445478,00 6978,00 Великопольские 3469464,00 17437,00 Западнопоморские 1717970,00 8183,00
В начале нам нужно рассчитать все необходимые данные для a и b
среднее арифметическое \ (\ overline {x} \): 2405247,31
среднее арифметическое \ (\ overline {y} \): 1178.50
\ (x- \ overline {x} \) \ (y- \ overline {y} \) \ ((x- \ overline {x}) * (y- \ overline {y}) \) \ ((x- \ overline {x}) ^ {2} \) 503209,69 1818,50 915086816,72 253219989593,85 -314411,31 -1486,50 467372416,03 98854473427,97 -253411,31 -869,50 2203411366,22 64217293302 , 97 -1384480,31 -6905,50 9560528797,97 1916785735700,10 103216,69 -375,50 -38757866,16 10653684578,47 958928,69 5580,50 5351301540,59 919544227710,47 2919271,69 131444740, 389 66 8522147185439,10 -1402672,31 -6958,50 9760495286,53 1967489616254,10 -276764,31 -493,50 136583188,22 76598484673,60 -1211899,31 -5645,50 6841777568.72 1468699943637,91-1064 -319.50 34006401,84 11328688618,60 2188110,69 10984,50 24035301846,84 4787828380751,72 -11398322,31 -5729,50 6530669234,47 1299217700619,10 -959769,31 -4802,50 4609292133168 920929213316 9292 1064216,69 5656,50 6019741692,84 1132557157953,47 -687277,31 -3597,50 2472480131,72 472350104277,22 115285667740,50 23922649799755,40
Что случилось в таблице выше? Сначала мы вычитаем x из среднего арифметического от x. Затем делаем то же самое для y. Умножаем индивидуальные различия (503209,69 * 1818,50 = 915086816,72). В последнем столбце мы имеем квадратичную разницу \ (x- \ overline {x} \). Эти большие жирные цифры внизу являются суммами отдельных столбцов. Мы просто подставляем эти значения в нашу формулу для:
\ (А = \ гидроразрыва {\ sum_ {= 1} ^ {N} (X_ {я} - \ Overline {х}) (у- {я} - \ Overline {у})} {\ sum_ {= 1 } ^ {п} (X_ {I} - \ Overline {х}) ^ {2}} \)
a = 115285667740,50 / 23922649799755,40 = 0,004819
Далее рассчитаем рассчитанные средние для формулы по b:
\ (В = \ Overline {у} -a \ Overline {х} \)
b = 11780,50 - 0,004819 * 2405247,31 = 189,37
И вуаля. Все рассчитано. Конечно, обычно это не делается вручную, на калькуляторе или даже путем ввода сумм и разниц в электронную таблицу. Я объясню вам, как это делается в различных программах, но сначала немного теории.
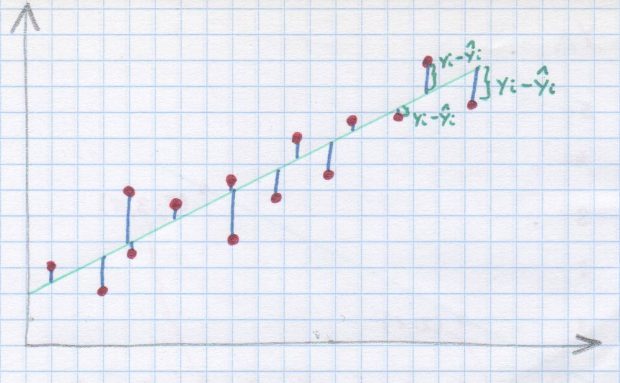
Какие остальные?
Когда мы уже вычислили параметры функции линейной регрессии, мы можем рассчитать, насколько наш экспериментальный y отличается от теоретического y, вычисленного из функции регрессии для конкретных значений x. Каждое такое различие называется остаточным или остаточным компонентом. Именно квадраты этих разностей мы минимизировали при расчете параметров a и B. И эти остатки могут сказать нам, правильно ли мы выбрали линейную регрессию в качестве метода оценки формы зависимости между переменными. Итак, давайте посмотрим на так называемые остаточный граф. Он показывает горизонтальную линию и точки, которые показывают, насколько наши остатки отклоняются от линии регрессии. Остальные должны быть достаточно равномерно распределены по одной стороне графика, предпочтительно как можно ближе к горизонтальной линии. Если мы видим четкое расположение, расположение точек не выглядит случайным, то, скорее всего, мы не имеем дело с нормальным распределением остальных. И, скорее всего, линейная регрессия не является наиболее оптимальным методом оценки y на основе x в этой ситуации.
Условия для метода наименьших квадратов
- Линейная зависимость - чтобы линейная регрессия имела смысл, должна существовать связь между переменными x и y, и эта связь должна быть линейной
- Нормальное распределение остатков - распределение остатков или вышеупомянутые различия между теоретическими y и y должны быть либо близки к нормальным, либо предпочтительно нормальным
- Постоянная дисперсия - распределение точек вокруг расчетной линии регрессии должно быть достаточно равномерным. Так что точки с одной стороны и с другой (и для низких, и для высоких значений x), как равномерно излучаются от этой линии.
- Независимые наблюдения - наблюдаемые переменные должны быть независимыми. В нашем случае количество браков в Великопольском воеводстве не должно зависеть от количества браков в Поморске или Свентокшиских. Также количество жителей одной провинции не должно зависеть от количества жителей другой.
Преимущества линейной регрессии (и метод наименьших квадратов)
- Я прочитал в учебнике, что «самое большое преимущество метода исследования - это его массовое применение на практике». И это самое большое преимущество линейной регрессии (и метод наименьших квадратов). Это так просто, что используется везде, где это возможно. Он используется математиками, геодезистами, астрономами, физиками, биологами, техниками, экономистами и, возможно, многими другими людьми.
- Расчеты можно легко сделать как вручную, так и с помощью различных статистических программ.
- Это ясно показывает, как выбросы являются проблематичными. То, что «вдвое дальше» от линии регрессии, более чем в два раза хуже, чем точка, которая находится ближе к линии регрессии. Это различие является значительным, например, по сравнению с методом, использующим абсолютное значение для оценки формулы функции.
Атипичные и влиятельные наблюдения
Атипичные наблюдения делятся на две основные группы:
- Используйте наблюдения - они имеют необычный x и довольно типичный y. Таким образом, они значительно удалены от других точек на горизонтальной оси.
- Выбросы ( выбросы ) - имеют типичные x и нетипичные y. Таким образом, они значительно удалены от вычисленного графика линейной регрессии, они имеют большой остаток. Говорят, что они не соответствуют уравнению регрессии.
Как выбросы, так и точки высокого рычага могут влиять на линию регрессии (изменение коэффициента направленности) или нет. Если они имеют такой эффект, их называют влиятельными наблюдениями. Их удаление вызывает большие изменения в расчетных параметрах А и В.
Примеры нетипичных наблюдений:
- Среди здоровых людей с типичным ростом и весом внезапно появляется человек, страдающий синдромом Прадера-Вилли (одним из симптомов этого заболевания является низкий рост и ожирение).
- Либеро среди волейболистов.
- Изучение уровня сгорания для различных марок автомобилей (например, в зависимости от веса) и среди этих автомобилей Тесла.
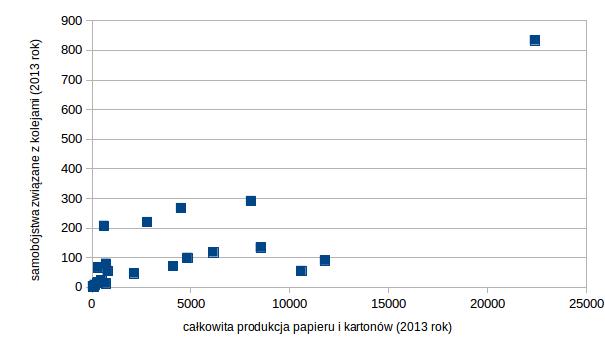
- Пример общего производства бумаги и картона и самоубийств, связанных с железными дорогами, в 2013 году для отдельных европейских стран. Мы смотрели на него по поводу расчета коэффициента корреляции, но здесь также здорово показать, что государством с высоким левериджем является Германия.
Оценка оценки регрессионной функции
стандартное отклонение остаточного компонента
Это стандартная ошибка уважения. Он сообщает, насколько в среднем эмпирические значения переменной отклоняются от теоретических значений, рассчитанных на основе оцененной функции регрессии. Шаблон выглядит ужасно, но это всего лишь иллюзия, потому что с худшим, что мы уже сделали:
\ (S_ {у} = \ SQRT {\ гидроразрыва {\ sum_ {= 1} ^ {N} (X_ {я} - \ шлем {у} _ {я}) ^ {2}} {N-2} } \)
коэффициент детерминации
Коэффициент определения определяет степень, в которой оценочная регрессионная функция объясняет изменчивость переменной y. Она принимает значения от 0 до 1. Чем ближе к 1, тем лучше адаптация регрессионной функции к эмпирическим данным.
\ (R ^ {2} = R_ {х} 2 ^ {} \)
коэффициент совместимости (сходимости)
Он указывает, какая часть изменчивости у не объясняется оценочной функцией регрессии. Он также принимает значения от 0 до 1. В отличие от коэффициента определения, чем ближе к 0, тем лучше будет соответствовать регрессионная функция. Его расчет очень прост, потому что достаточно вычесть значение коэффициента детерминации из 1
\ (\ Varphi ^ {2} = 1-Р ^ 2} {\)
коэффициент остаточной изменчивости
\ (V = \ S_ {гидроразрыва} {у} {\ Overline {у}} * 100 \% \)
Коэффициент остаточной изменчивости сообщает о том, какой процент уровня объясненной переменной является случайными колебаниями. Чем ближе к 0, тем лучше настройка функции регрессии.
критерий значимости для коэффициента линейной регрессии
Не было статистического теста на статистическую значимость. Итак, не вдаваясь в детали, позвольте мне просто сказать, что такой тест есть, и проверить в нем, существенно ли коэффициент направленности a отличается от 0. Итак, мы проверяем, имеет ли смысл использовать вычисленную функцию регрессии вообще. Потому что если коэффициент направленности равен нулю, это означает, что не имеет смысла использовать такую функцию, потому что изменение x не влияет на изменение y.
Линейная регрессия в электронной таблице
В качестве объяснения. Я использую рабочий лист LibreOffice Calc. Весьма вероятно, что не каждая электронная таблица работает одинаково - стоит воспользоваться помощью программы и прочесть разницу.
диаграмма
Простейшие параметры регрессии (с готовым графиком) можно определить, щелкнув правой кнопкой мыши одну из точек и выбрав опцию, которую мы хотим добавить линию тренда (в моей английской версии это «Вставить линию тренда»), а затем выбрав, что мы хотим что уравнение регрессии видно (английская версия «Показать уравнение»). Нас интересует график линейной регрессии - вы можете видеть, что есть много разных вариантов.
LINEST (ЛИНЕЙН) функция
Другая возможность узнать параметры a и b (и много другой информации) - использовать функцию LINEST (версия на польском языке) или LINEST (версия на английском языке). Мы выбираем эту функцию из набора функций массива (Array). Мы приводим последовательно: диапазон ячеек для y, диапазон ячеек для x, информацию о том, должно ли b быть равно 0 (0, если да, 1, если нет), информацию, если нужно посчитать другую статистику (1, если да).
Если мы введем их всего, то в итоге получим таблицу:
0,004819101090619 189,3000053122613 0,000116509255482 314,367367529241 0,991883338921891 569,855925338422 1710,84718349985 14 555573287,140994 4546300,85900633
Индивидуальная информация в таблице идет слева сверху:
а = 0,0048
б = 189,37
стандартная ошибка a = 0,00012 (расчетная средняя ошибка, ошибка оценки параметра)
стандартная ошибка b = 314,37
коэффициент детерминации = 0,9919
стандартная ошибка y, стандартное отклонение случайной составляющей
Значение F статистики
количество степеней свободы для F статистики
регрессивная сумма квадратов
сумма остаточных квадратов
Статистический пакет в электронной таблице
Данные -> Статистика -> Регрессия
Мы предоставляем входные данные и в результате получаем таблицу:
Регрессия Модель регрессии Линейный R ^ 2 0,991883338921891 Стандартная ошибка 569,855925338427 Наклон 0,004819101090619 Перехват 189, 370053122613
В Excel все по-другому, к сожалению, в настоящее время у меня нет доступа, поэтому, если кто-то использует Excel, он может установить Analysis ToolPack и самостоятельно поэкспериментировать.
Линейная регрессия в R
Мы знаем, как выглядят расчеты в электронной таблице. Сейчас я покажу вам, как бороться с линейной регрессией в R. Я представляю тот же пример, который мы уже посчитали «вручную» и используя функцию в Calc:
линейная регрессия в R-коде
dane1 <- read.csv (, ~ / Desktop / regresja_data.csv ')
брак <- данные о браке1
население <- данное1 $ населения
модель1 = лм (брак ~ население)
сюжет (брак ~ население, основной = "регрессионный график")
abline (model1)
Сущность (model1)
пары (mfrow = с (2,2)); участок (Model1) пар (mfrow = с (1,1))
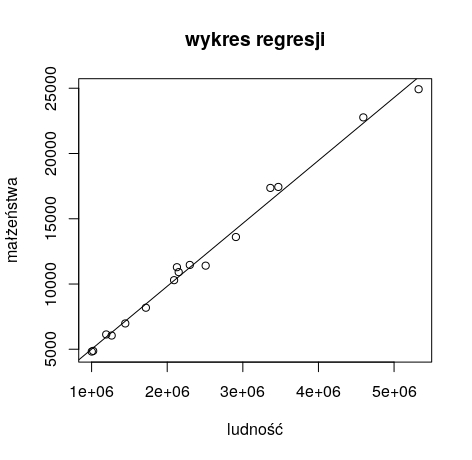
линейная регрессия в R - графе
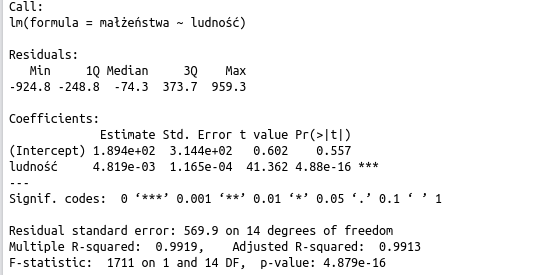
линейная регрессия в R - расчетные параметры
Какую информацию мы получили?
Минимальные и максимальные значения и квартили для отдыха.
Значение коэффициента направления и свободного выражения наряду с информацией о стандартном отклонении и статистическими значениями t.
Стандартное отклонение остаточного компонента.
Коэффициент детерминации и скорректированный коэффициент детерминации (последний более полезен для моделей с большим количеством объясняющих переменных).
Значения для статистики F (которая изучает значимость модели в целом)
линейная регрессия в R - остаточные графы
В дополнение к графику линейной регрессии, в R мы можем очень легко получить четыре графика, которые очень полезны для остаточного анализа.
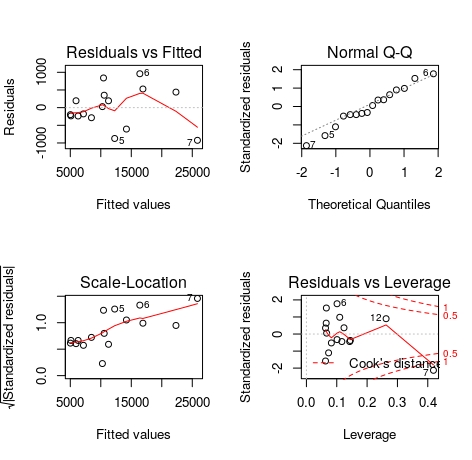
На первом графике («Остатки против подгонки») по горизонтальной оси приведены значения, соответствующие объясненной переменной (y), а по вертикальной оси - остаточные значения. В идеале известно, если бы они все были на горизонтальной линии в нуле (это идеальное совпадение). Мы заинтересованы в том, чтобы красная линия была как можно более прямой и прямой. Этот график позволяет проверить, действительно ли отношения между x и y являются линейными.
График "Normal QQ" - это квантильный граф для нормального распределения. Для нас важно, чтобы отдельные точки были как можно ближе к пунктирной линии. Этот график позволяет нам проверить, выполняется ли условие нормального распределения остатков.
Диаграмма «Масштаб - местоположение» на горизонтальной оси показывает значения, соответствующие объясненной переменной (y), а на вертикальной оси - элементы из стандартизированных модулей невязок. Хорошая модель должна иметь равномерно расположенные точки вдоль горизонтальной оси. Этот график позволяет проверить предположение об однородной дисперсии (так называемая гомоскедастичность).
Диаграмма «Остатки против плеча» помогает обнаружить влиятельные наблюдения. Здесь мы имеем дело с расстоянием Кука (означает меру степени изменения коэффициентов регрессии, если случай был опущен при вычислении коэффициентов). Нас интересуют те случаи, которые выходят за пределы красных, нанесенных на карту линий. Чем выше значение, тем больше наблюдение влияет на значения коэффициента регрессии.
Мы можем видеть, что в случае наших графиков выделяется седьмое наблюдение. Если мы посмотрим на наши данные, мы можем проверить, что это данные по провинции Мазовия. Вы можете догадаться, что столица существенно влияет на наши расчеты. И вы должны спросить себя, будет ли лучшая модель, которая не использовала бы провинцию Мазовия.
линейная регрессия - удаление данных из модели
Я написал, что можно подумать о том, следует ли удалять явно несопоставимые точки из нашей модели. Да. У нас всегда есть возможность производить расчеты без влиятельных наблюдений. Но при принятии такого решения необходимо тщательно обдумать, оправдано ли оно. Необходимо учитывать, что послужило источником отклонения данных от других. И, давая интерпретацию модели, всегда следует информировать, что было принято решение удалить из нее необычные наблюдения. Поскольку однажды произошло что-то «странное», мы никогда не знаем, случится ли это снова в будущем. А анализируя на основе «улучшенной» модели, нужно помнить, что в некотором смысле мы исключаем ненормальные случаи.
Интерполяция и экстраполяция
Когда мы уже знаем формулу на нашей прямой линии, мы можем попытаться предсказать значения y для известных значений x.Если у нас есть класс 1a, и мы знаем вес и рост 25 учеников, то мы можем вычислить линию линейной регрессии в соответствии с нашими предыдущими предположениями. И если мы узнаем, что Томек присоединяется к классу, который измеряет 122 см, мы можем заменить x на функцию и вычислить вероятный вес для нее. Конечно, мы не можем быть уверены, что у Томека будет именно такой большой вес. Потому что, возможно, Том любит пончики, слойки и шоколад, и за это 90% времени он проводит за игрой на планшете в «конфеты» и поэтому весит на 10 килограммов больше, чем средний семилетний ребенок. И, может быть, у Томека ноги как палки, и хотя его родители кормят его хлебом с салом, они все еще не могут его немного достать и боятся, что, если подует ветер, Томек уйдет, он такой худой. Наш прогноз веса Tomek не будет на 100% уверен, но если Tomek довольно средний ученик нашего класса, благодаря линейной регрессии, мы сможем предсказать его вес не плохо. И это случай интерполяции. Мы заинтересованы в случае где-то еще в таблице.
Мы экстраполируем, когда мы хотим предсказать y для x вне тестируемого диапазона. И здесь вы должны быть осторожнее. Потому что трудно оценить вес трехлетней сестры Томек (рост 95 см) или его тридцатилетней матери (которая может похвастаться ростом на 165 см) на основе расчетов, выполненных для первоклассников.
Дополнительная информация о линейной регрессии
Помните, что, как и корреляция, линейная регрессия говорит о линейных отношениях между двумя переменными, но ничего не говорит о причинно-следственной связи. Мы можем попытаться предсказать значение одной переменной на основе другой (например, увеличение на основе веса), но, изменяя одну, мы не обязательно изменим значение другой (если мы уменьшим наш просроченный платеж, он не будет ниже).
Если линейная регрессия все еще вызывает сомнения, я рекомендую два интересных видео на YouTube:
Статистика в человеческом голосе - как рассчитать параметры линейной регрессии
Скорая медицинская помощь - по линейной регрессии в SPSS
Я думаю, что после прочтения вышеприведенной статьи и просмотра фильмов вы сможете разобраться с ответом, что такое линейная регрессия и как ее рассчитать.
Уфффф ... Я готовил эту статью для тебя больше месяца. Я надеюсь, что оно того стоило и что можно было объяснить наличие и детали линейной регрессии. У меня все еще есть впечатление, что я все еще могу много писать, но я хотел, чтобы статья сопровождала вас. Если вы считаете, что это стоит прочитать, поделитесь ссылкой с друзьями. Между тем, я рад, что победил своего слона 😉

Приглашаю вас неизменно Fanpage статистический.
На Facebook всегда появляются информация о новых записях и напоминания о старых статьях.
Я также напоминаю вам, что это стоит использовать оглавление где я стараюсь быть в курсе всех статей блога.
карта разума: линейная регрессия
Пожалуйста, следуйте и нам нравится:
Похожие
Какие 3D-очки самые лучшие?На этот вопрос нет однозначного ответа, а премьера «Аватара» является причиной дальнейших сомнений в выборе подходящего кинотеатра с подходящими очками. В мире четыре кинотеатра сталкиваются с конфликтом в кинозале клиента, каждый из которых предлагает чуть более современное оборудование, чем классические бумажные рамки с красной и зеленой фольгой. Тот же принцип похож - один глаз видит один кадр, другой видит немного другое, и в результате мы видим «глубину» в данном изображении. Календарные дни или рабочие дни, или как ...
Автор: Анна Стемпневская Дата: 4 сентября 2018 г. Гражданский кодекс определяет порядок исчисления сроков. Уставный принцип имеет большое значение с точки зрения деятельности предпринимателя. Это будет применяться, например, к осуществлению покупателями прав в соответствии с Законом о правах потребителей Каковы условия получения ипотеки для бизнеса?
... rc="/wp-content/uploads/2019/11/ru-kakovy-uslovia-polucenia-ipoteki-dla-biznesa-1.jpg" alt="Деловая активность , и, следовательно, ведение бизнеса самостоятельно, независимо от того, является ли она компанией, состоящей из одного человека, или предприятием, на котором работает большее количество сотрудников, представляет определенную трудность, когда дело доходит до подачи заявления на получение ипотеки"> Деловая активность , и, следовательно, ведение бизнеса самостоятельно, LIFO
... вым пришел - первым вышел) относится к тому, как: - материалы хранятся на складе, - потребительские товары оцениваются и облагаются налогом Принцип действия Принцип похож на вертикальную кучу, которая используется для метода ФИФО , Разница в том, что элементы доступны в том же порядке, в котором они были добавлены ранее. Это означает, что первый («нижний») элемент берется последним. На следующем Изменение условий трудового договора
работодатель он должен заключить с ним контракт, прежде чем позволить работнику работать , в котором он определяет, среди прочего, вознаграждение, должность, объем обязанностей. А что если работодатель захочет изменить условия договора? Какие изменения в условиях трудового договора и чем это может закончиться? Интерпретация соотношений возможностей процессов Cp и Cpk
Необходимость изучения коэффициентов мощности процесса широко известна в автомобильной промышленности. Типичным требованием заказчика является то, что поставщик должен достичь определенных минимальных уровней возможностей процесса для выбранных характеристик, в частности для специальных Какой тип домашнего хранилища данных мне выбрать?
Домашние пользователи все чаще сталкиваются с проблемой покупки небольшой матрицы - вот краткое руководство. Приглашаем вас прочитать запись гостя, специально подготовленную для наших читателей Дэниелом Мауэрфоэром из Western Digital. Выбирая решения для хранения данных для домашнего и малого или среднего бизнеса, у нас теперь есть два варианта - мы можем создать локальное хранилище файлов или использовать сервис поставщика услуг для «облачного» хранения. В обоих сегментах мы находим статистические методы вкладки данных
... rong>Маркетинговые исследования Referujący: Петр Гнациковский II группа Павел Антонюк группа II ... вашей лицензии Origin действующий договор на обслуживание? Проверить почему это важно! Программа ...
... вашей лицензии Origin действующий договор на обслуживание? Проверить почему это важно! Программа Origin - это пакет, который позволяет получать, анализировать и визуализировать данные измерений. Ряд инструментов позволяет пользователю импортировать данные и размещать их на листе. Следующим этапом является обработка собранных данных, уже сделанных пользователем. Многие встроенные функции используются IWP - База данных дизайнеров и предпринимателей. Держатель карты
Держатель карты - это база данных дизайнеров и компаний, которые инвестируют в дизайн бесплатно, доступны на портале Wzornictwo-Biznes-Zysk, без входа в систему. Это единственная база Как пользоваться порталом
Оглавление Пользовательское Соглашение Создание проекта Добавление соавторов Организация данных Описание Проекта Метаданные Загрузка и
Комментарии
Какие функции предоставляет бесплатный пакет на портале?Какие функции предоставляет бесплатный пакет на портале? Вы можете отправлять 1 сообщение в день (система удалит старые сообщения, если в почтовом ящике их более 30), разделить 100 сообщений в месяц, просмотреть профили и добавить их в избранное. Бесплатный профиль не ограничен по времени, а также Какие функции камеры определяют этот предел?
Какие функции камеры определяют этот предел? И если у нас есть правильные навыки, мы можем переместить это? Мы ответим на эти вопросы, используя примеры фотографий, снятых с помощью зеркальной камеры Sony α550. Несколько выбранных условий съемки позволят вам понять, как фотографировать в сложных условиях освещения. - - - - - - - - - - - - - - - - - - РЕКЛАМА - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Достаточно ли функций для использования в вашем следующем проекте, или вы продержитесь, прежде чем добавить несколько светодиодных ламп в свой персональный пакет освещения?
Достаточно ли функций для использования в вашем следующем проекте, или вы продержитесь, прежде чем добавить несколько светодиодных ламп в свой персональный пакет освещения? Какие условия должен выполнять сайт в настоящее время?
Какие условия должен выполнять сайт в настоящее время? Прежде всего: быстро загрузить . Второе: иметь уникальный контент . В-третьих: будьте « дружелюбны к мобильным устройствам » (это руководство будет особенно важным с нового года). Тем не менее, адаптация его к текущим требованиям поисковых систем является ключевым действием, предпринимаемым, если вы хотите в полной мере использовать потенциал SEO. Мы подготовили для вас бесплатный Бульонные монеты - какие из них самые прибыльные?
Бульонные монеты - какие из них самые прибыльные? Крюгерранд и Американский Орел - несмотря на примесь других металлов, все еще содержат 1 унцию чистого золота. Инвестирование ETF - означает инвестирование в фонд, который является индексом нескольких десятков компаний, занимающихся, например, добычей золота или покупкой слитков или сертификатов. Как и в случае фондов или акций, брокер взимает небольшую комиссию с транзакции. Несомненным преимуществом является тот факт, что инвестиции Какие транзакции включают освобождение от пошлины?
Какие транзакции включают освобождение от пошлины? Освобождение от таможенной пошлины регулируется в Регламенте Европейского сообщества № 80/2012 от 31 января 2012 года, в нормативных актах Комиссии ЕС № 1224/2011 и 1225/2011 Какие предпосылки для преступления?
Какие предпосылки для преступления? Ответ на эти вопросы содержится в уголовном кодексе. Самый важный рецепт - статья 286 KK . Мошенничество в уголовном кодексе описывается следующим образом: Статья 286 КК § 1. Кто бы ни, чтобы получить финансовую выгоду, ведет другого человека к неблагоприятному регулированию своим собственным имуществом путем введения в заблуждение или использования ошибки или неспособности Какие видеокарты и процессоры самые лучшие?
Какие видеокарты и процессоры самые лучшие? Интернет-форумы также задают аналогичные вопросы, потому что ситуация на рынке компонентов быстро меняется, и трудно идти в ногу с новинками, которые расстраивают предыдущие идеи. Перед покупкой компьютера средний пользователь сталкивается с серьезными проблемами, которые неразрывно связаны с его деньгами, что должно стать сильным стимулом для поиска лучших решений. В конечном счете, не всем нужно знать, какой процессор или видеокарту стоит выбрать, Поэтому, прежде всего, вам необходимо четко определить - что мы можем ожидать, какие преимущества мы получим от установок с солнечными коллекторами и / или солнечными батареями?
Поэтому, прежде всего, вам необходимо четко определить - что мы можем ожидать, какие преимущества мы получим от установок с солнечными коллекторами и / или солнечными батареями? МЫ ВЫБИРАЕМ КОЛЛЕКТОРЫ И ЭЛЕМЕНТЫ - КАК БОЛЬШАЯ УСТАНОВКА? Прежде всего, нет оснований ожидать, что благодаря коллекторам у нас будет горячая вода на весь год. Это не только вопрос размера установки, потому что зимой, во время заморозков, антифриз нагревается до слишком низкой температуры. На какие вопросы стоит обратить внимание при покупке электронных весов?
На какие вопросы стоит обратить внимание при покупке электронных весов? Контрольные весы и весы Электронные весы можно разделить на два основных типа: контрольные весы и весы. Первыми являются простые устройства, которые указывают только вес взвешиваемых товаров. Контрольные весы характеризуются низкой ценой, небольшими размерами и простотой использования. Они часто оснащены батареей или батареями и используются при продаже от двери Какие образцы пищи?
Какие образцы пищи? Что такое образцы пищевых продуктов, как их следует собирать и хранить, регулируется постановлением министра здравоохранения от 17 апреля 2007 года о сборе и хранении образцов пищевых продуктов предприятиями общественного питания закрытого типа. Образцы каждой составной части пищи из пищевой партии отбираются в конце периода испытаний в количествах, необходимых для проведения лабораторных испытаний (не менее 150 г). Мы храним образцы в пластиковой
Что случилось в таблице выше?
Какие остальные?
А что если работодатель захочет изменить условия договора?
Какие изменения в условиях трудового договора и чем это может закончиться?
Вашей лицензии Origin действующий договор на обслуживание?
Вашей лицензии Origin действующий договор на обслуживание?
Какие функции предоставляет бесплатный пакет на портале?
Какие функции камеры определяют этот предел?
И если у нас есть правильные навыки, мы можем переместить это?
Достаточно ли функций для использования в вашем следующем проекте, или вы продержитесь, прежде чем добавить несколько светодиодных ламп в свой персональный пакет освещения?